
AI-Based Framework to Accelerate Flow Simulation
This page contains a summary of my master's thesis, which was conducted in collaboration with Imperial College London and SLB. I created an artificial intelligence model that predicts subsurface CO2 flow with greater speed than traditional physics-based simulators. Unlike other studies, the aim here is not to reach a general reservoir model, but to train the models specifically for the reservoir and task at hand. To make this technology accessible, I also crafted a user-friendly web application that facilitates both the training and prediction processes.
Web Application Video

The web application is designed in a modular fashion, making it easy to add new features. I utilized an open-source package called webviz-config, in addition to Python's Plotly and Dash libraries for development. The repository structure is as follows:
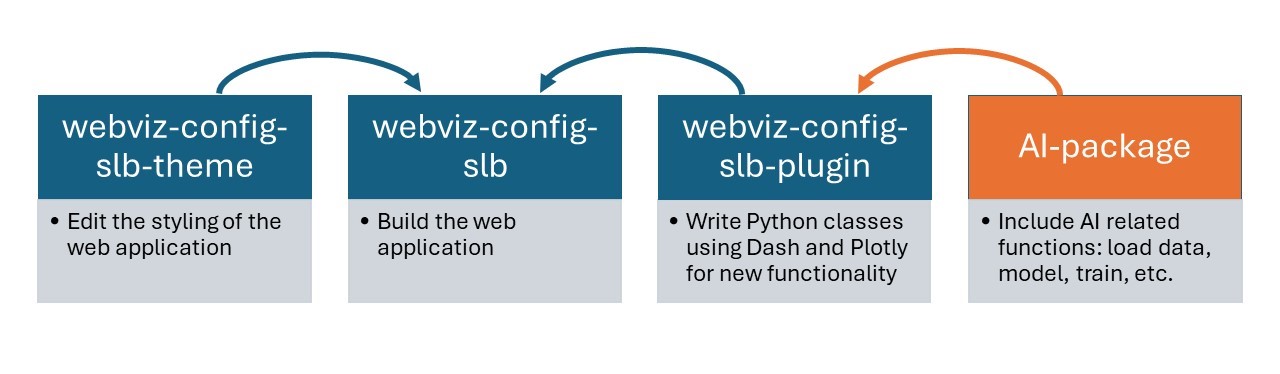
Data flow in the web application is shown in the below diagram:

Inputs and Outputs
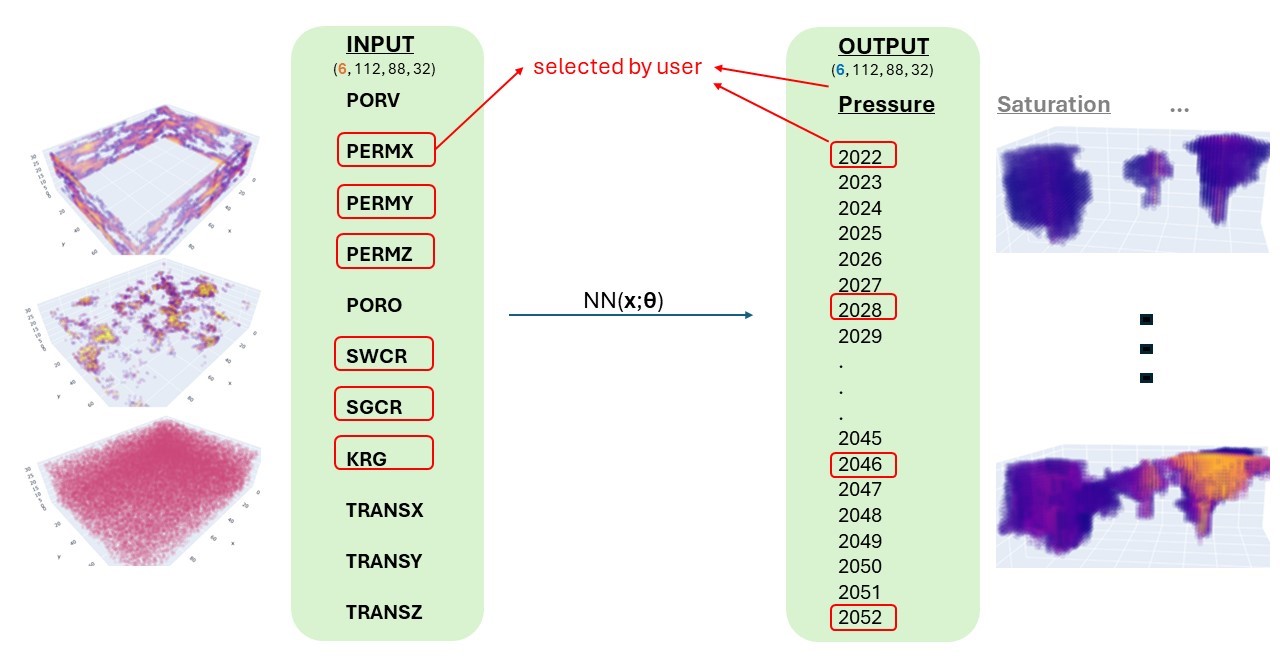
The user can select arbitrary number of inputs out of 35 static reservoir properties and arbitrary number of outputs out of 17 dynamic reservoir properties and they can decide on the time step resolution. The model is automatically generated on the fly according to the user's selections. This offers huge flexibility as not all reservoirs have uncertainty in the same attributes.
Neural Network Architecture
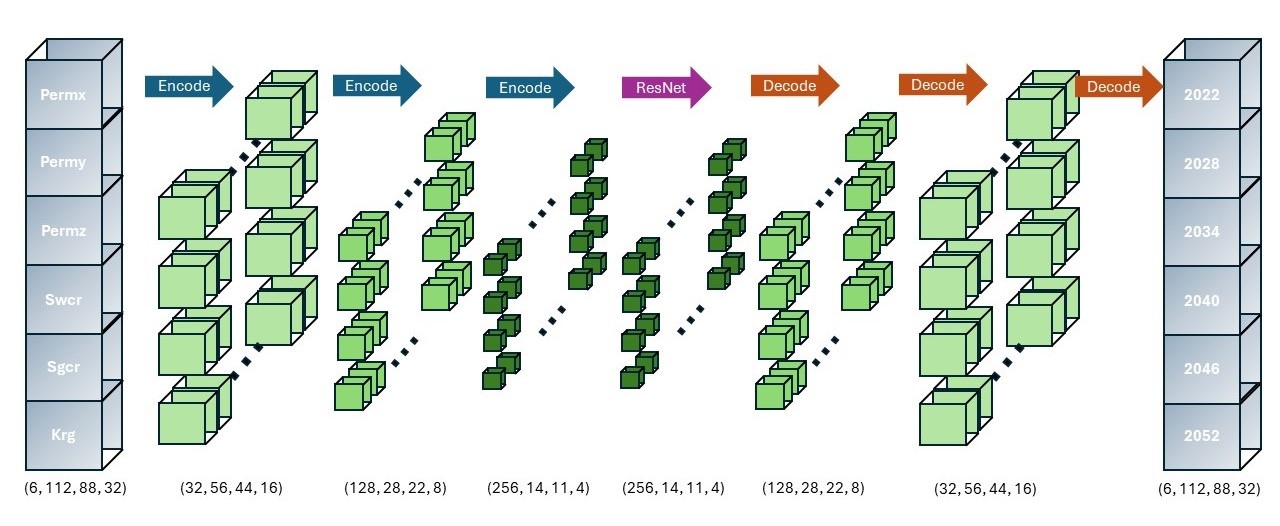
I designed an encoder-decoder architecture using convolutional layers to handle 4-dimensional inputs. I incorporated residual connections to increase the depth of the network. Additionally, batch normalization was implemented to regularize the model and facilitate the learning process. The ReLU activation function was utilized in all layers except the output layer.
Comparison
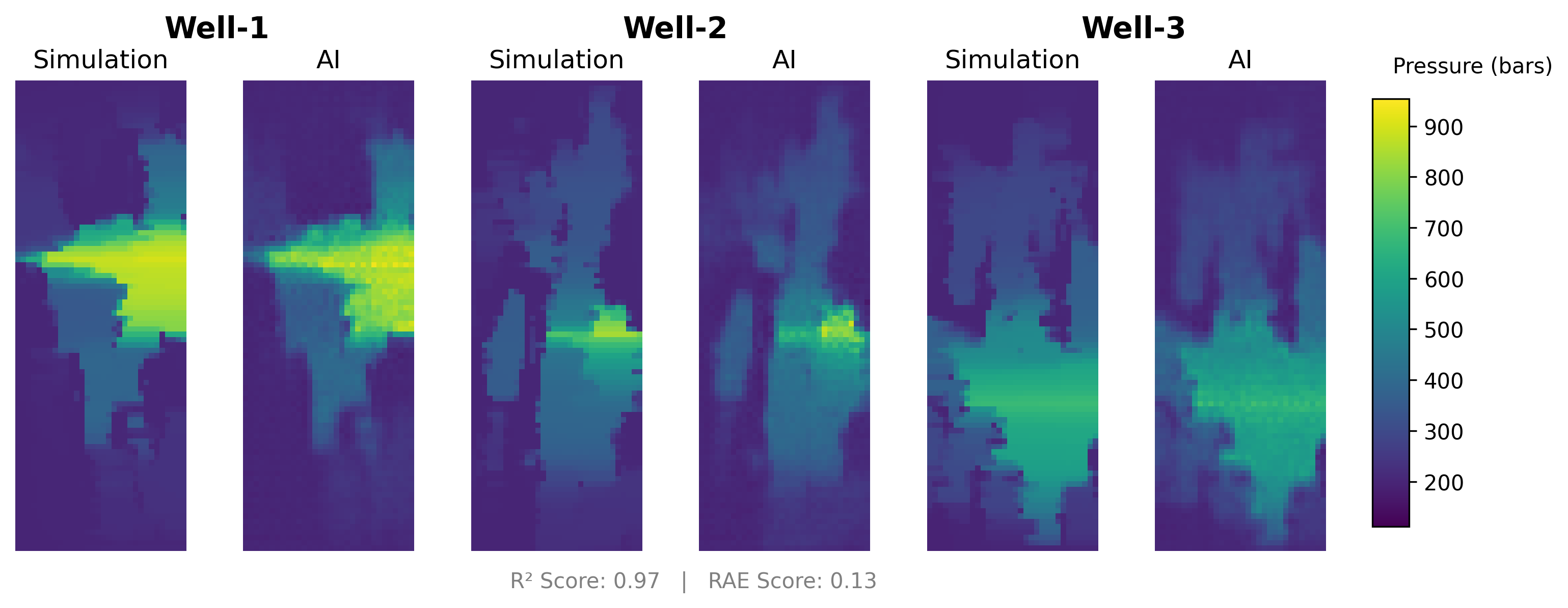
AI predictions closely resemble the physics simulation, as shown in the comparison figure. AI predictions are generated in less than a second, while the physics simulation takes 5 minutes.
Code Avaliability
Some portion of the source code is available in this GitHub repository. The Python packages required to process the raw Intersect data are confidential and not shared. At the moment, the data is not publicly available. Because of these, reproducing the same functionality is not possible. Still, the pages other than data loading would work fine.
More information will be available once the paper is published. For further inquiries, please contact me via email.